自然言語処理ライブラリのGiNZAを使って係り受け解析を試す

Photo by Florian Olivo on Unsplash
はじめに
自然言語処理ライブラリのGiNZAを使って係り受け解析を行ってみたのでその手順をまとめます。
できるようになること
以下のように、指定した文章の係り受け木を作成して、単語間の修飾関係を可視化してみます。また、条件に合致する文章の検索、名詞節の抽出も行います。
参考文献
この記事を書くにあたって、以下の記事を参考にさせて頂きました。大変勉強になりました。またこちらの執筆者様にコメント頂きこの記事の作成に至りました。ありがとうございます。
私(安岡孝一)の一昨昨日の日記の読者から、GiNZAも紹介してほしい旨の御意見をいただいた。実は4月29日の日記で、さりげなく紹介してるのだけど、とりあえずpip3でGiNZA 1.0.2をインストール。 % pip3 install https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz ...
前提と環境
以下の通りです。
- OS : Ubuntu18.04
- Python 3.7
- GiNZAはインストール済とする。
2019年4月に株式会社リクルートのAI研究機関であるMegagon Labsから、Python向けの日本語自然言語処理オープンソースライブラリ「GiNZA」(ギンザ)が公開されました(プレスリリースのリンクは以下)。GiNZAには国立国語研究所との共同研究成果の学習済モデルが組み込まれているそうです。この記事では、GiNZAをインストールして簡単に使ってみるまでの手順をまとめます。
条件に合致する文を探す
以下は、夏目漱石の「吾輩は猫である」の冒頭部分が保存されたsouseki.txtというテキストファイルを読み込み、その中で「目的語+見る」という文を探して見つけた目的語を表示します。
import spacy
nlp = spacy.load('ja_ginza_nopn')
# ファイルを開く
test_data = open("souseki.txt", "r")
# ファイルの中身を保存する
contents = test_data.read()
# ファイルを閉じる
test_data.close()
doc = nlp(contents)
for sent in doc.sents:
for token in sent:
if token.dep_=="obj":
if token.head.lemma_=="見る":
print("文: " + sent.text)
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.head.text)
print("\n")
なお、上記で読み込むsouseki.txtは以下の内容となります。
吾輩は猫である。名前はまだ無い。
どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。この書生というのは時々我々を捕えて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。のみならず顔の真中があまりに突起している。そうしてその穴の中から時々ぷうぷうと煙を吹く。どうも咽せぽくて実に弱った。これが人間の飲む煙草というものである事はようやくこの頃知った。
この書生の掌の裏でしばらくはよい心持に坐っておったが、しばらくすると非常な速力で運転し始めた。書生が動くのか自分だけが動くのか分らないが無暗に眼が廻る。胸が悪くなる。到底助からないと思っていると、どさりと音がして眼から火が出た。それまでは記憶しているがあとは何の事やらいくら考え出そうとしても分らない。
ふと気が付いて見ると書生はいない。たくさんおった兄弟が一疋も見えぬ。肝心の母親さえ姿を隠してしまった。その上今までの所とは違って無暗に明るい。眼を明いていられぬくらいだ。はてな何でも容子がおかしいと、のそのそ這い出して見ると非常に痛い。吾輩は藁の上から急に笹原の中へ棄てられたのである。
ようやくの思いで笹原を這い出すと向うに大きな池がある。吾輩は池の前に坐ってどうしたらよかろうと考えて見た。別にこれという分別も出ない。しばらくして泣いたら書生がまた迎に来てくれるかと考え付いた。ニャー、ニャーと試みにやって見たが誰も来ない。そのうち池の上をさらさらと風が渡って日が暮れかかる。腹が非常に減って来た。泣きたくても声が出ない。仕方がない、何でもよいから食物のある所まであるこうと決心をしてそろりそろりと池を左りに廻り始めた。どうも非常に苦しい。そこを我慢して無理やりに這って行くとようやくの事で何となく人間臭い所へ出た。ここへ這入ったら、どうにかなると思って竹垣の崩れた穴から、とある邸内にもぐり込んだ。縁は不思議なもので、もしこの竹垣が破れていなかったなら、吾輩はついに路傍に餓死したかも知れんのである。一樹の蔭とはよく云ったものだ。この垣根の穴は今日に至るまで吾輩が隣家の三毛を訪問する時の通路になっている。さて邸へは忍び込んだもののこれから先どうして善いか分らない。そのうちに暗くなる、腹は減る、寒さは寒し、雨が降って来るという始末でもう一刻の猶予が出来なくなった。仕方がないからとにかく明るくて暖かそうな方へ方へとあるいて行く。今から考えるとその時はすでに家の内に這入っておったのだ。ここで吾輩は彼の書生以外の人間を再び見るべき機会に遭遇したのである。第一に逢ったのがおさんである。これは前の書生より一層乱暴な方で吾輩を見るや否やいきなり頸筋をつかんで表へ抛り出した。いやこれは駄目だと思ったから眼をねぶって運を天に任せていた。しかしひもじいのと寒いのにはどうしても我慢が出来ん。吾輩は再びおさんの隙を見て台所へ這い上った。すると間もなくまた投げ出された。吾輩は投げ出されては這い上り、這い上っては投げ出され、何でも同じ事を四五遍繰り返したのを記憶している。その時におさんと云う者はつくづくいやになった。この間おさんの三馬を偸んでこの返報をしてやってから、やっと胸の痞が下りた。吾輩が最後につまみ出されようとしたときに、この家の主人が騒々しい何だといいながら出て来た。下女は吾輩をぶら下げて主人の方へ向けてこの宿なしの小猫がいくら出しても出しても御台所へ上って来て困りますという。主人は鼻の下の黒い毛を撚りながら吾輩の顔をしばらく眺めておったが、やがてそんなら内へ置いてやれといったまま奥へ這入ってしまった。主人はあまり口を聞かぬ人と見えた。下女は口惜しそうに吾輩を台所へ抛り出した。かくして吾輩はついにこの家を自分の住家と極める事にしたのである。
上記の実行結果は以下です。
$ python check-obj.py
文: 吾輩はここで始めて人間というものを見た。
もの 物 NOUN NOUN obj 見
文: 掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。
顔 顔 NOUN NOUN obj 見
文: ここで吾輩は彼の書生以外の人間を再び見るべき機会に遭遇したのである。
人間 人間 NOUN NOUN obj 見る
文: これは前の書生より一層乱暴な方で吾輩を見るや否やいきなり頸筋をつかんで表へ抛り出した。
吾輩 我が輩 PRON PRON obj 見る
文: 吾輩は再びおさんの隙を見て台所へ這い上った。
隙 隙 NOUN NOUN obj 見
名詞節を抽出する
名詞とその名詞に係る単語を与えた文から抽出して表示します。
import spacy
nlp = spacy.load('ja_ginza_nopn')
doc = nlp("私はお腹がとても空いている。昼食を早く取りたい。")
for chunk in doc.noun_chunks:
print(chunk.text, chunk.root.text, chunk.root.dep_, chunk.root.head.text)
実行結果は以下のようになります。
私 私 iobj 空い
お腹 お腹 nsubj 空い
昼食 昼食 obj 取り
簡単な例ですが、名詞とそれに係る単語を抽出できていることが分かります。上記について記載されているspaCyのドキュメントは以下です。
spaCy is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
係り受け木を表示する
係り受け解析を行って単語間の修飾関係をツリー構造で表示します。
以下のスクリプトを実行すると、与えた文の係り受け木を端末上に表示することができます。以下ではnltkが必要となるため、pip install nltkなどでインストールしておいてください。
import spacy
from pathlib import Path
from nltk import Tree
nlp = spacy.load('ja_ginza_nopn')
doc = nlp("吾輩は猫である。名前はまだ無い。")
# tree表示するトークンのフォーマット
def token_format(tk):
# トークンのorth_、dep_、pos_の3つをトークンの情報として含める
return "_".join([tk.orth_, tk.dep_, tk.pos_])
# tree表示する関数
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(token_format(node), [to_nltk_tree(child) for child in node.children])
else:
return token_format(node)
[to_nltk_tree(sent.root).pretty_print() for sent in doc.sents]
実行結果は以下です。文単位で表示されます。
猫_ROOT_NOUN
__________|__________________________
| | | 吾輩_nsubj_PRON
| | | |
で_aux_AUX ある_aux_AUX 。_punct_PUNCT は_case_ADP
無い_root_ADJ
_____________|_____________
| | 名前_nsubj_NOUN
| | |
まだ_advmod_ADV 。_punct_PUNCT は_case_ADP
なお、上記のスクリプトは以下を参考にさせて頂きました。
I have been trying to find how to get the dependency tree with spaCy but I can't find anything on how to get the tree, only on how to navigate the tree.
係り受け木をブラウザからアクセスして確認する
spaCyでは、係り受け木を確認するためにWebサーバーを起動してブラウザからアクセスして確認も可能です。displacy.serveを使用します。
import spacy
from spacy import displacy
nlp = spacy.load('ja_ginza_nopn')
doc = nlp("吾輩は猫である。名前はまだ無い。")
displacy.serve(doc, style="dep")
上記を実行すると、以下のようにWebサーバーが起動して待機状態になります。
$ python show-tree-web.py
Using the 'dep' visualizer
Serving on http://0.0.0.0:5000 ...
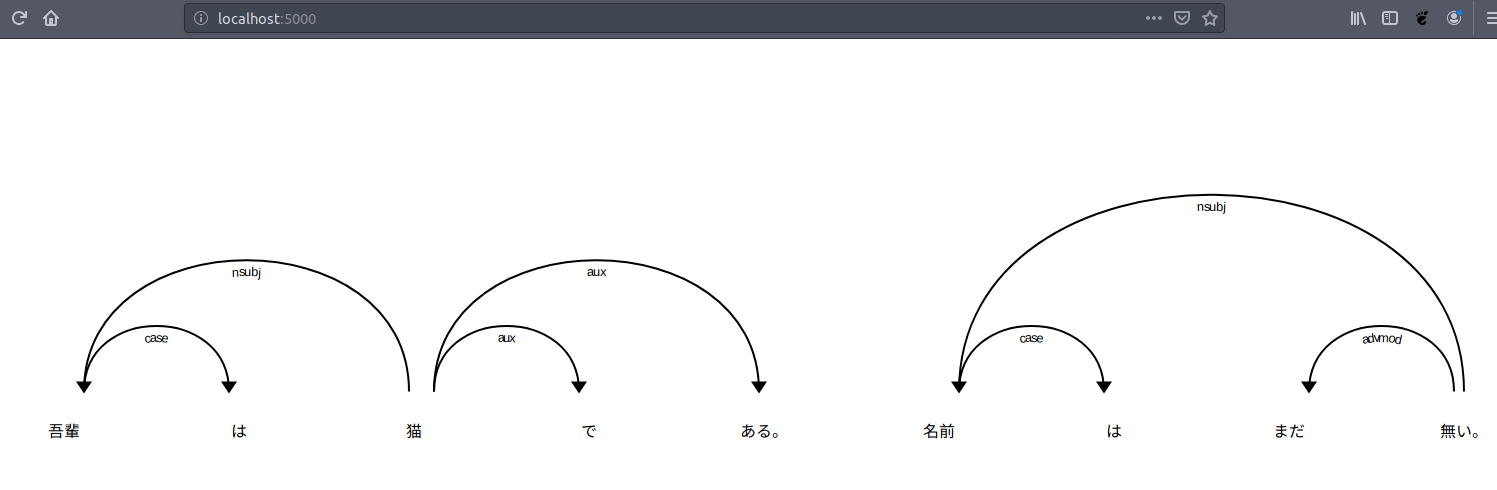
あとはブラウザからlocalhost:5000にアクセスすると、以下のように係り受け木を確認できます。なお、上記スクリプトファイルを実行している端末にlocalhostでアクセスできることが前提となります。
係り受け木をSVGファイルに保存する
SVG形式のファイルに保存することも可能です。以下を実行すると、与えた文章の各文について係り受け木をSVG形式でファイルに保存します。
import spacy
from spacy import displacy
from pathlib import Path
nlp = spacy.load('ja_ginza_nopn')
doc = nlp("吾輩は猫である。名前はまだ無い。")
for sent in doc.sents:
svg = displacy.render(sent, style="dep")
# svg = displacy.serve(doc, style="dep")
file_name = sent.text + ".svg"
output_path = Path("./images/" + file_name)
output_path.open("w", encoding="utf-8").write(svg)
上記を実行すると、吾輩は猫である。.svg、名前はまだ無い。.svgという2つのファイルがimagesというディレクトリ内に作成されます。なお、このimagesディレクトリは、上記スクリプトファイルと同じディレクトリ内に作成済であることを前提としていますので、各自の環境に合わせて変更してください。
上記について記載されているspaCyのドキュメントは以下です。
spaCy is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
まとめ
GiNZAでできることはまだまだ多いので、色々と調べてより実用的な応用例をまた載せれればと思います。
関連記事
 公開日:2019/11/19 更新日:2019/11/19
公開日:2019/11/19 更新日:2019/11/19AIによって自動生成した人物写真をダウンロードできるギャラリーサイト「25,000 AI Photos」
「25,000 AI」はAIで自動生成した人物のフォトギャラリーサイトです。サイトにアクセスすると分かりますが、色々な地域の方の男女の人物写真が公開されています。これらは全て実在する人物ではなくAIによって自動生成されているようです。
 公開日:2019/05/30 更新日:2019/05/30
公開日:2019/05/30 更新日:2019/05/30News APIへの登録とPythonでニュースを取得するまでの手順
News APIは、いくつかのニュースサイトからトップニュースや条件指定して合致したニュースをJSON形式で取得できるAPIです。2019年5月時点では30,000ほどのニュースサイト等のソースに対応しています。この記事では、実際にNews APIを使用してニュースを取得するまでの手順をまとめます。
 公開日:2019/05/29 更新日:2019/05/29
公開日:2019/05/29 更新日:2019/05/29自然言語処理ライブラリGiNZAをインストールして簡単に動かすまでの手順
2019年4月にPython向けの日本語自然言語処理オープンソースライブラリ「GiNZA」(ギンザ)が公開されました(プレスリリースのリンクは以下)。GiNZAには国立国語研究所との共同研究成果の学習済モデルが組み込まれているそうです。この記事では、GiNZAをインストールして簡単に使ってみるまでの手順をまとめます。
 公開日:2019/05/28 更新日:2019/05/28
公開日:2019/05/28 更新日:2019/05/28テキストの有害度をスコア化できるGoogleのPerspective APIをPythonで使う手順
GoogleのプロジェクトのJigsawの中の1つに、与えられた文字列がどれぐらい有害であるかを色々な指標でスコア化するPerspective APIというプロジェクトがあります。この記事では、このPerspective APIをPythonで実際に動かしてみるところまでの手順をまとめます。